
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
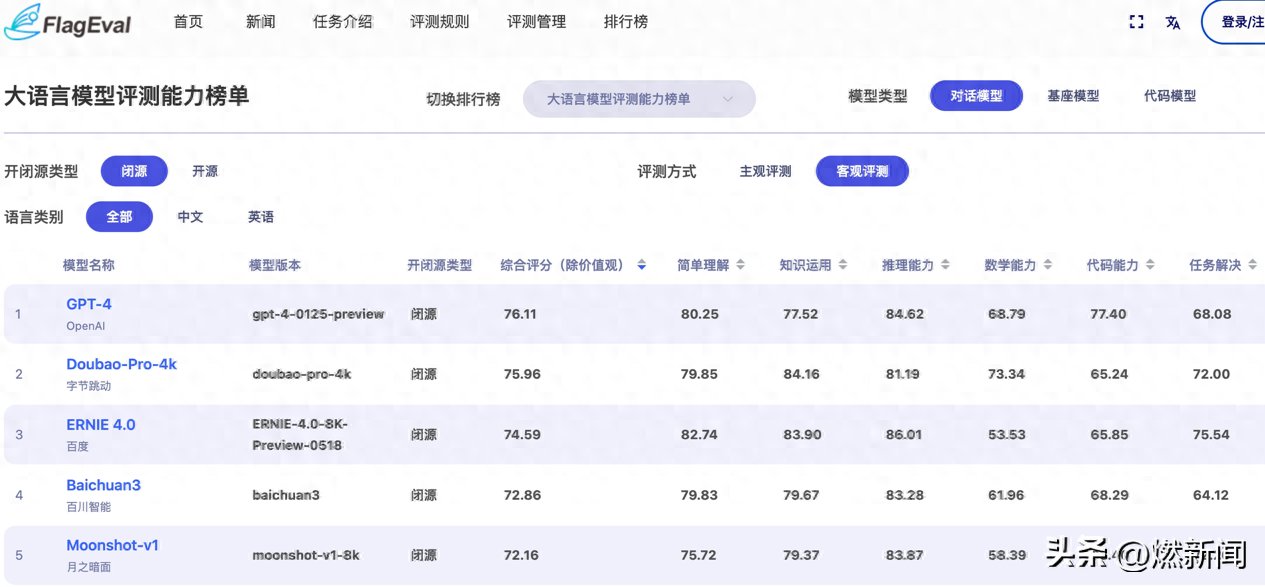
智源更新大模型排行榜:豆包大模型“客观评测”排名国产第一
24
0
相关文章
近七日浏览最多
最新文章
标签云
华为
杭州
小米
oppo
vivo
智能手机
市场份额
黑马
广告
潘粤明
白夜破晓
迪卡普里奥
电池容量
reno
中国电信
卫星
骁龙
一加手机
研究院
刘作虎
苹果公司
苹果
摩托罗拉
红米note
安卓
小米10
android
pi
世界知识产权组织
中国信息通信研究院
美国专利商标局
丰田公司
丰田
金融科技
港元
广发证券
黑石集团
千元机
a3
realme
拼多多
lg
三星
维信诺
oled
显示屏
lcd
pdd
联发科天玑
战神
防水
处理器
卡顿
高通
红魔
cpu
游戏
折叠屏
苹果手机
tcl
小米mix
中国证券报
谅解备忘录
ultra
京东方
香港联交所
关联方