Her,正从电影,走向现实。
今年 5 月,OpenAI 发布最新 AI 多模态大模型 GPT-4o。相比此前的 GPT-4 Turbo,GPT-4o 速度快了两倍,成本低了一半,实时的 AI 语音互动的平均时延,相比此前版本的 2.8 秒 (GPT-3.5) 到 5.4 秒 (GPT-4),更是达到了 320 毫秒——与人类日常对话响应速度几乎一致。
不仅是效率的提升,对话中的情感分析也成为了此次产品更新的特色之一。在与主持人的对话中,AI 可以听出他说话时的「紧张」,并且针对性的提出了深呼吸的建议。
OpenAI,正成为大模型时代硅基的「造物主」。
然而,发布会很震撼,现实却很骨感。产品落地上,这场大模型技术革命的发起方 OpenAI,正逐渐变得像一家「期货」公司。
主打全能、低时延的 GPT-4o 发布后,实时音视频功能的上线迄今仍在跳票;视频多模态产品 Sora 发布,同样迟迟不见开放。
但这不只是 OpenAI 一家企业的问题——ChatGPT 发布后,国内国产版 ChatGPT 多如过江之鲫,但是真正对标 GPT-4o 的,目前却只有一个商汤的日日新 5.5,进度也同样停留在月内公测。
为什么发布会上,实时多模态大模型距离变革世界只有一步之遥;在真正走向产品化落地的过程中,却总是「现货」变「期权」?
一种新的声音正在浮出水面:在多模态的世界里,或许(算法)暴力无奇迹。
01 实时语音,一条必经的AI 商业化路线
技术的成熟,正助推一个崭新的蓝海产业逐渐成型。
硅谷知名风投机构 a16z 数据显示,全球用户量 Top50 AI 应用中,9 款是陪伴型产品。AI 产品榜数据则显示,今年 5 月 AI 伴侣的访问量高达 4.32 亿,同比增长 13.87%。
高需求、高增速、高市场空间,AI 陪伴,带来的是商业模式与人机交互的双重变革。
商业的成熟,也在反向倒逼技术的不断进步。仅以今年上半年为节点,实时 AI 语音技术在短短六个月,就已经发生了三次迭代。
第一波技术浪潮的代表性产品是 Pi。
今年 3 月,初创企业 Inflection AI 更新了面向个人用户的情感聊天机器人 Pi。
Pi 的产品界面非常简洁,文本+对话框是核心交互界面,但也增加了语音读取,电话等 AI 语音功能的设计。
实现这种语音交互,Pi 依靠的是传统的 STT(语音识别,Speech-to-Text)-LLM(大模型语义分析)- TTS(文本到语音,Text To Speech)三步走的语音技术。其特点是技术成熟,但反应慢,缺乏对语气等关键信息的理解,无法做到真正的实时语音对话。
与之同期的另一款特色产品是 Call Annie。相比 Pi,Call Annie 有完整的视频通话体验设计,除了接挂电话的设计之外,听话功能还可以最小化之后切入其他 App,并支持四十多种对话角色设定。
然而它们都有着共同的技术问题——高时延与情感色彩缺乏。时延上,即是行业内最先进的 OpenAI,也会出现 2.8 秒(GPT-3.5)到 5.4 秒(GPT-4)的延迟。情感上,则会出现在交互中丢失如音调、音高、语速等信息,更无法做到输出笑声、唱歌声等高级语音表达
在此之后,新一波技术的代表则是一款名叫 EVI 的产品。
这款产品在今年 4 月由 Hume AI 推出,并为 Hume AI 带来了 5000 万美元(约 3.62 亿人民币)的 B 轮融资。
产品设计上,Hume AI 在底层算法环节推出了 Playground 功能,用户可以自己选择配置选择大模型,除了官方默认,还可以选择像 Claude、GPT-4 Turbo 等。但不同之处是语音带上了情感,因此在表达上,也有了节奏、语调的变化。
实现这一功能,主要依靠在传统的 STT-LLM- TTS 三步走环节中,加入新的 SST(semantic space theory,语义空间理论)算法。SST 能通过广泛的数据收集和先进的统计模型,精准绘制人类情感的全谱图,揭示人类情感状态之间的连续性,使得 EVI 具备很多拟人化的特色功能。
情感进步的代价,则是时延的进一步牺牲,与 EVI 对话,用户需要等待的时间,相较 Pi 与 Call Annie 进一步增加。
到了 5 月中旬 GPT-4o 发布,融合多模态技术成为这一时期的技术方向标。
与过去的三步式语音交互产品相比,GPT-4o 是一款跨文本、视觉和音频端到端训练的新模型,这意味着所有输入和输出都由同一个神经网络处理。
时延问题也因此被极大改善。OpenAI 官宣,GPT-4o 的实时语音交互,可以做到最快 232 毫秒、平均 320 毫秒的响应音频输入。情感上,用户与 AI 的交互也变得越来越有智能属性,语速变化、情感理解得到实现。
产品层面,人类与 AI 谈恋爱、AI 替代盲人看世界也因此成为可能。
前不久推出语音电话功能、2024 年硅谷引人瞩目的新星——Character.ai,就成为了这次技术浪潮中的最大受益者。
在 Character.ai,用户有机会在超逼真的角色扮演中与动漫人物、电视名人和历史人物的摹本发短信。新奇的设定带来了产品用户数量的暴增,根据 Similarweb 的数据,Character.ai 每秒可以处理 20000 个 AI 推理请求,5 月的访问量高达 2.77 亿。
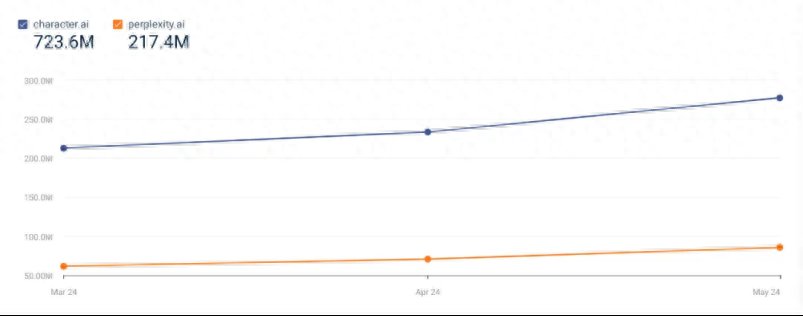
Character.ai 和 perplexity.ai 的流量对比|图片来源:Similarweb
与之同期,微软、谷歌等纷纷官宣旗下的大模型将推出实时语音通话功能。
然而滴水不漏的产品设计,在现实执行中,却总是呈现出三峡泄洪的落地效果——第三波浪潮之中,发布会上几近「her」式的陪伴产品,在实际落地中,全部变成了「计划」推出、即将推出、内测中。
一个毫无疑问的结论是,实时音视频有可能成为人机互动终极形态,除了AI陪伴场景外,游戏智能 NPC、AI 口语老师、实时翻译等场景都有望迎来爆发,但在此之前,如何解决「发布会」到产品落地的最后一公里,是当下行业最棘手的难题。
02 AI 实时语音,大力无奇迹
AI实时语音「大力无奇迹」,一个悲观的说法正在硅谷悄悄蔓延。
阻力则来自技术、监管以及商业的方方面面。
技术上的反对派精神领袖,是「卷积网络之父」杨立昆(Yann LeCun)。
在他看来:大模型技术,相比过去的各种 AI 算法,最大的特点是「大力出奇迹」。通过大数据投喂,以及动辄上亿参数体量与高性能的计算集群硬件支持,算法由此可以用于处理更复杂的问题,以及更高的可扩展性。然而,我们当前对于大模型过于乐观,尤其是多模态大模型可能就是世界模型的观点,更是无稽之谈。
比如,人有五感,才组成我们对于世界的真实认知,基于大量互联网文本训练的 LLM,缺乏对物理世界的观察与互动,也缺乏足够多的常识。因此生成视频或者语音的过程中,总是会出现看似天衣无缝的内容,运动轨迹,或者声音情感中,却缺乏真实感。此外,硬性的物理限制也是问题,面对与日俱增的模型大小以及交互维度,目前的大模型缺乏足够的带宽处理如此信息。
监管层面,AI实时语音,也就是端到端的语音大模型,面临的是技术与伦理的博弈。
过去,传统的 AI 语音产业 STT-LLM- TTS 的三步走,首先是技术不成熟所导致,进化到端到端的语音大模型需要在模型架构、训练方法和多模态交互等方面实现额外的技术突破。同时,也是由于语音本身的监管难度高于文字,导致 AI 语音极易被用至电话诈骗、色情以及垃圾营销等场景。为了便于审核,中间的文字环节,也在一定程度上变得必要。
而在商业层面,端到端的音视频大模型训练,在训练阶段,需要大量 YouTube 以及播客的数据,成本是过去文字训练模型的几十倍甚至更高,一次训练成本千万美金起步。
而这种成本,对于此时的普通 AI 企业来说,天上掉钱都已经没用,还得一起掉下英伟达高端 AI 算卡、千兆存储还有取之不尽的无风险音视频版权。
当然,无论是杨立昆的技术判断,还是可能的监管难题,亦或是商业化的成本困境,这些对 Open AI 来说,都算不上最核心的问题。
真正让 GPT-4o 类实时AI语音交互类产品现货变期货的根本原因,出在工程落地层面。
03 插着网线演示的 GPT-4o,还差一个好用的 RTC 助攻
一个业内心照不宣的秘密是,GPT-4o 类AI实时语音产品,在工程层面,只成功了一半。
GPT-4o 的发布会上,宣称低延时的同时,有眼尖的用户发现,演示视频中的手机,还插着网线。这也就意味着:GPT-4o 官宣的平均 320ms 时延,很可能是固定设备、固定网络、固定场景的 demo,在理想状态下才能达成的实验室指标。

OpenAI 的 GPT-4o 发布会现场明显可见手机插线|图片来源:OpenAI
问题出在哪里?
从技术层面拆解,要实现 AI 实时语音通话,算法层面的三步合为一步,只是其中核心环节之一,另一个核心环节 RTC 通信层面,也面临一系列技术挑战。所谓 RTC,可以简单地理解为在实时的网络环境下进行音视频的传输和交互, 是一种支持实时语音、实时视频等互动的技术。
声网音频技术负责人陈若非告诉极客公园,在实际落地的应用场景中,用户通常无法一直处于固定设备、固定网络和固定物理环境下。在我们日常进行视频通话场景中,一方的网络不佳后,就会出现说话卡顿、延迟变高的现象,这种情况同样会出现在 AI 实时语音通话中,所以低延时的传输、优异的网络优化对 RTC 传输至关重要。
此外,多设备适配、音频信号的处理等也是 AI 实时语音落地中不容忽视的技术环节。
如何解决这些问题?
答案就藏在 OpenAI 最新的招聘需求中,OpenAI 特地提到,要招聘工程人才,帮助他们把最先进的模型部署到 RTC 环境中。
具体的方案选择上,GPT-4o 使用的 RTC 技术,是一种基于 WebRTC 的开源方案,可以在技术层面解决一定的时延,以及不同网络环境带来的丢包、通信内容安全,以及跨平台的兼容问题。
然而开源的 B 面,则是产品化的薄弱。
举个简单的例子,多设备适配问题,RTC 的使用场景大多以手机为代表,但不同型号手机的通信、声音采集能力千差万别:目前苹果手机已经可以做到大约几十毫秒的稳定延时,但是生态较为复杂的 Android 生态,不仅机型多、高端与低端产品的性能差距也颇为明显,部分低端型号设备,在采集与通信层面,时延就能高达几百毫秒。
再比如,AI 实时语音应用场景中,人的语音信号可能会混杂了背景噪声,需要进行复杂的信号处理,移除噪声和回声,确保干净、高质量的语音输入,让 AI 更能听懂人说的话。
多设备的兼容性、先进的音频降噪的能力也正是开源 WebRTC 所欠缺的。
行业经验,是开源产品在应用中的卡脖子难题。也是因此,相比开源方案,大模型厂商与专业的 RTC 方案商一起打磨共同优化,一定程度上更能代表未来的行业趋势。
在 RTC 领域,声网是最具代表性的厂商,曾因为对 Clubhouse 提供音频技术而广为人知,根据声网官网的消息显示,全球超 60% 泛娱乐 App 选择声网的 RTC 服务,除了国内知名的小米、B 站、陌陌、小红书等 App 外,中东及北非地区最大的语音社交与娱乐平台 Yalla、东南亚「社交直播平台之王」Kumu、HTC VIVE 、The Meet Group、Bunch 等遍布全球的知名企业均采用了声网的 RTC 技术。

行业经验的积累,全球化客户的打磨,更是技术领先的佐证。据陈若非介绍,声网自研的 SD-RTN™ 实时传输网络覆盖了全球 200 多个国家与地区,音视频的全球端到端延迟平均达到 200ms。针对网络环境的波动,声网的智能路由技术与抗弱网算法,可以保障通话的稳定性与流畅性。针对终端设备的差异性,声网更是积累了全球上亿 App 预装以及对复杂环境适配积累的 know-how。
技术领先之外,行业经验更是无形的壁垒。
事实上,这也是为什么这些年来,RTC 行业商业格局较为稳定的原因:做好 RTC,依靠的,从来不是大模型式的「大力出奇迹」。
日积月累的深耕细作,才是语音延迟极致优化和实时语音交互能普遍商用的唯一途径。
而从这一角度来看,AI实时语音交互,是一场在想象力以及难度上都不应被低估的战争。
它的未来——算法、审核、RTC 一关一关都要过。要走完这漫长的道路,既要仰望技术的星空,更要脚踏工程化的实地。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com