
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
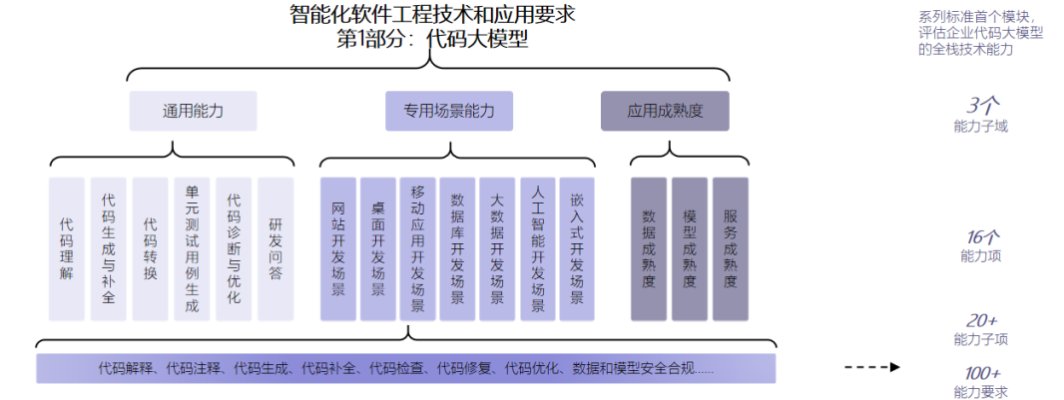
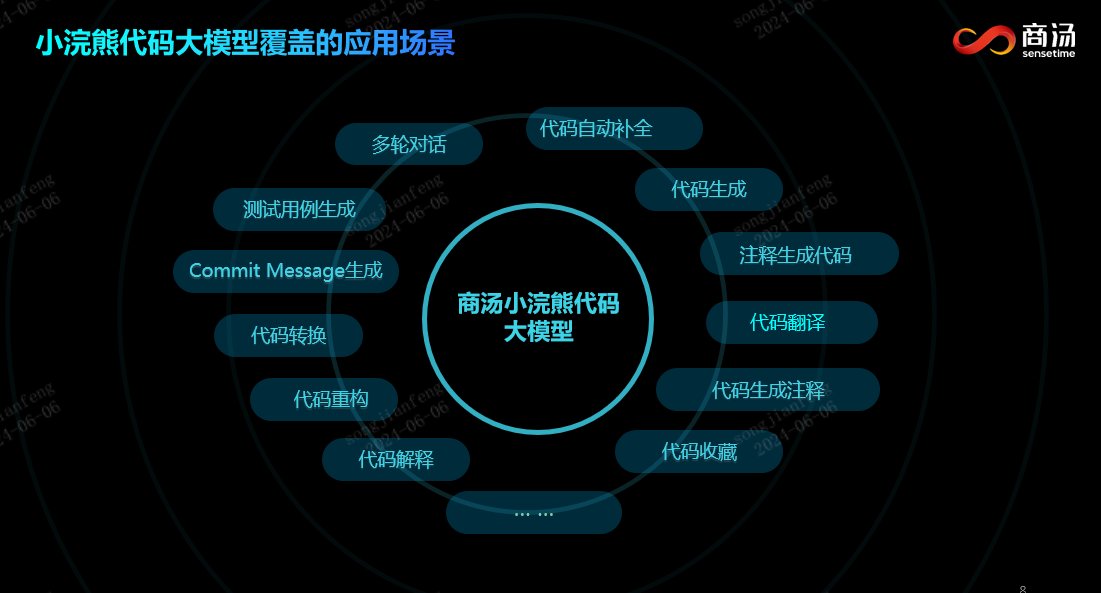
首批通过,最高评级,商汤小浣熊喜提中国信通院代码大模型能力评估“三好生”
15
0
相关文章
近七日浏览最多
最新文章
标签云
金山办公
上海证券交易所
指数
金融界
a股
数据宝
操作系统
创业板指
日本央行
证券
保险
板块
科创板日报
寒武纪
科创板
中华诗词
人工智能
pilot
云计算
alphabet
北向资金
今日头条
番茄
字节跳动
主力资金净流入
kimi
净流入
中国软件
科大讯飞
游族网络
三七互娱
证券投资基金
大盘
基金经理
华宝
混合型
博时基金
基金
风控
ipo
公募基金
etf
时代周报
百济神州
西安
天津
数字经济
华泰证券
投资
华夏基金
黑客
java
apple
苹果公司
苹果
amazon
亚马逊
ibm
职场
卡内基
梅隆大学
加拿大
app
游戏
虚拟世界
射击游戏
cuda
鸿蒙
华为
微软
adobe
阿里云
rain
商汤
初创公司
ui
microsoft
pdf
谷歌
谷歌公司
chro
腾讯云
甲骨文
清华
清华大学
世界500强
清华北大
快科技
php
奥运会
乒乓球
ar
商汤科技
中国国家队
篮球
奥运
商朝
东汉
战争
司马
孔子
伊尹
夏桀
东风
智能汽车
机器人
更上一层楼
科技
吉利
mpv
广汽
自动驾驶
小巴
特斯拉
6g
李彦宏
中国移动
研究院
网易
恒瑞医药
申万宏源
国泰君安
周朝
古代
中国历史
英特尔
展锐
中国信息通信研究院
土方
中国工商银行
turbo
深交所
股票上市规则
中国海洋石油
资金净流入
药明生物
小米集团