5月14日OpenAI线上举办“春季更新”发布会,推出新旗舰模型GPT-4o,并宣布免费向用户提供更多ChatGPT功能。华泰研究电子团队、传媒团队,从技术亮点、模型效果、应用场景、投资机会的角度,对此联合解读。
电子 GPT-4o:时延大幅缩短,有望加速AI硬件落地
传媒 GPT-4o发布,语音和视觉交互升级
电子 GPT-4o:时延大幅缩短,有望加速AI硬件落地
GPT-4o:时延大幅缩短,有望加速AI硬件落地
北京时间5月14日凌晨,OpenAI发布其首个端到端多模态模型GPT-4o。我们认为本次发布的主要亮点是大幅缩短的大模型响应时延。根据公司披露,GPT-4o语音模式平均时延320毫秒,与人类在对话中的响应时间相似,而GPT-3.5及GPT-4的时延分别为2.8秒和5.4秒,这为大模型在手机,耳机等移动设备上的应用落地铺平了道路。该模型实际的部署形式(纯云端 vs 云端-手机端混合)有待公司进一步披露。根据彭博报道,苹果和 OpenAI接近达成iOS聊天机器人协议。关注大模型在终端产品落地对手机/PC销量,端侧算力需求的带动。
技术亮点:端到端多模态模型,时延大幅降低
GPT-4o支持文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出。GPT-4o时延大幅降低,语音模式下最短232毫秒,平均时延320毫秒,与人类在对话中的响应时间相似,而GPT-3.5及GPT-4的时延分别为2.8秒和5.4秒。我们认为GPT-4o时延降低得益于:1)全栈优化,OpenAI表示过去2年中花费大量精力提升每一层堆栈的效率;2)端到端模型,多模态的输入和输出都由同一神经网络处理。而在GPT-4中,语音模式由三个独立模型组成,分别负责将音频转录为文本、接收文本并输出文本、将该文本转换回音频,导致GPT-4丢失了大量信息——无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
模型效果:多语言、音频和视觉功能上优于GPT-4 turbo
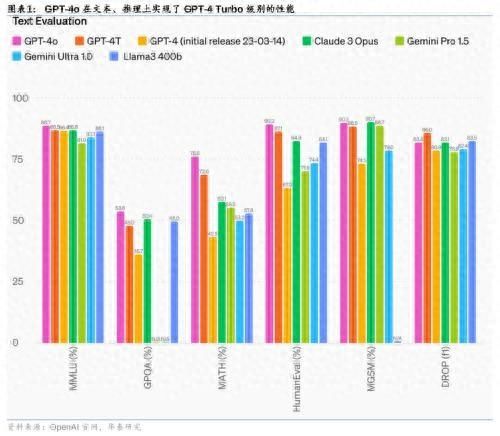
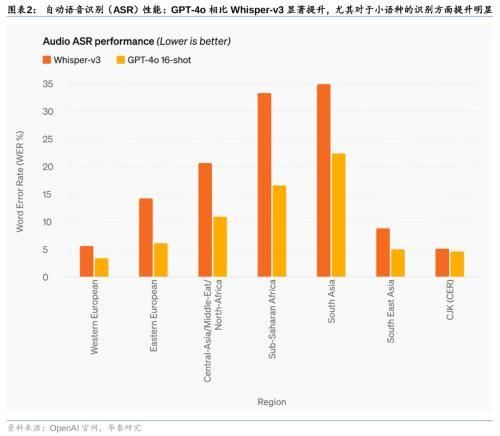
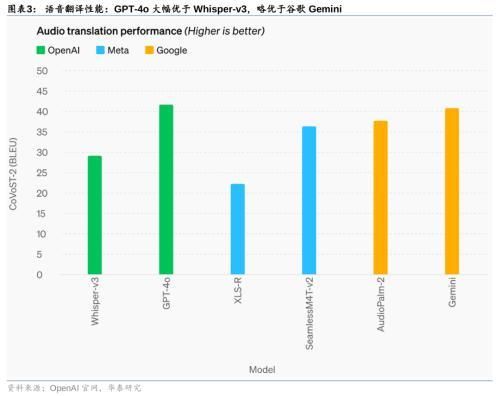
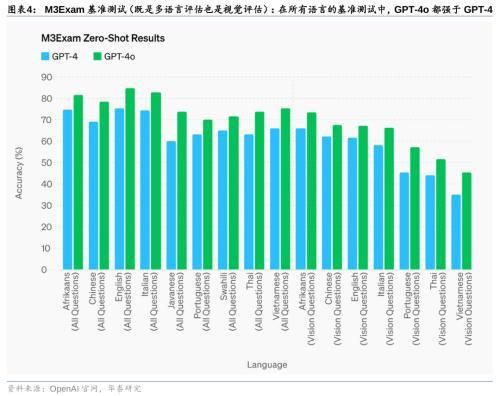
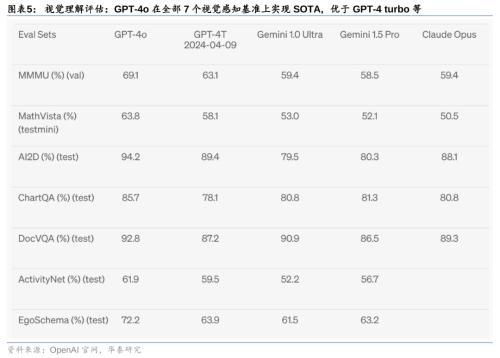
GPT-4o在文本、推理和编码智能方面实现了GPT-4 Turbo级别的性能,在多语言、音频和视觉功能上性能更优:1)自动语音识别(ASR)性能:GPT-4o相比Whisper-v3显著提升,尤其对于小语种的语音识别方面提升明显;2)语音翻译性能:GPT-4o大幅优于Whisper-v3,略优于谷歌Gemini;3)M3Exam基准测试(既是多语言评估也是视觉评估):在所有语言的基准测试中,GPT-4o都强于GPT-4;4)视觉理解评估:GPT-4o在全部7个视觉感知基准上实现SOTA(state-of-the-art),优于GPT-4 turbo等。
应用:低时延+多模态创造沉浸式体验
GPT-4o在人机交互上有以下特点:1)通过用户语音和表情识别用户情感;2)可以随时打断模型的语音输出,模型调整后重新输出,而没有交流过程中的停顿;3)以不同的情感风格生成语音。我们认为以上特点得益于GPT-4o的端到端多模态架构。此外,GPT-4o还能够生成3D模型、在多轮对话中具备高度一致性的虚拟角色形象,在设计、漫画创作等领域具备落地可能性。
行业观点:看好AI大模型落地手机、智能穿戴、智能家居、PC等硬件
我们认为GPT-4o大幅提升人机交互体验,具备在手机、智能穿戴设备、智能家居产品、PC等硬件产品上落地的广阔空间。近期,我们注意到AI大模型硬件落地节奏加快:1)根据彭博报道,苹果和 OpenAI接近达成iOS聊天机器人协议。建议投资人关注6月11日举行的苹果WWDC 2024;2)根据The Information报道,Meta正在探索开发带有摄像头的AI耳机,希望用于识别物体和翻译外语。2024年4月Meta发布Llama 3时,宣布雷朋智能眼镜将搭载Llama 3,将具备文本翻译、视频直播、物体识别等功能。
风险提示:AI 及技术落地不及预期;本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。
研报《GPT-4o:时延大幅缩短,有望加速AI硬件落地》2024-05-14
本文源自券商研报精选
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com