友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
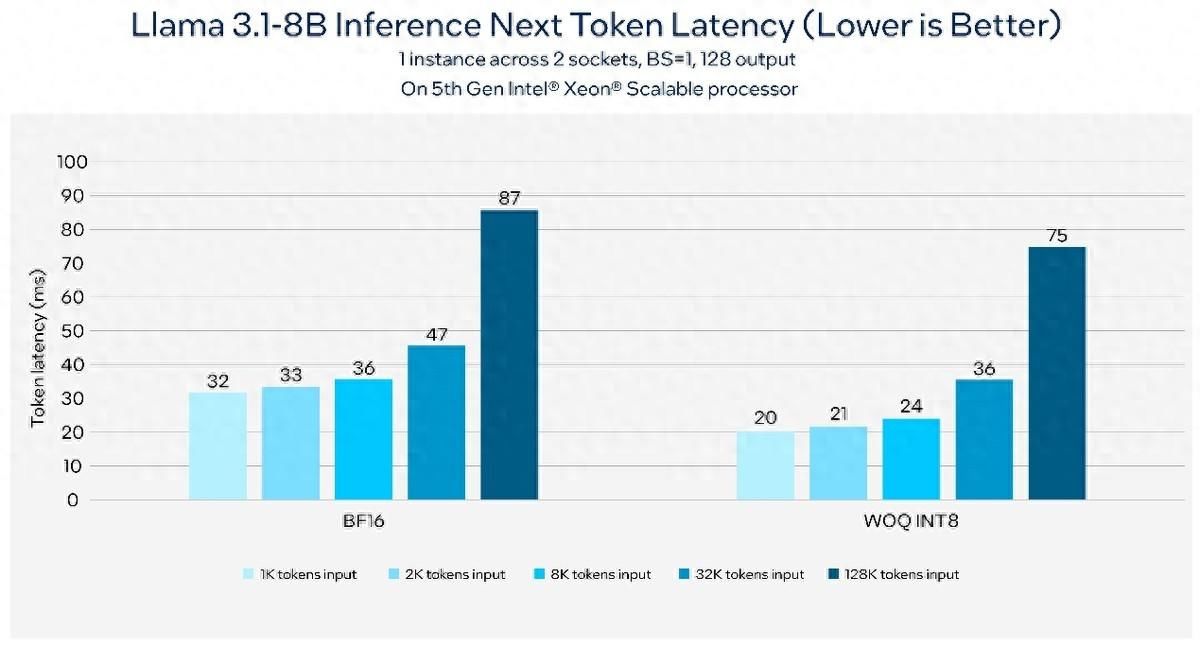
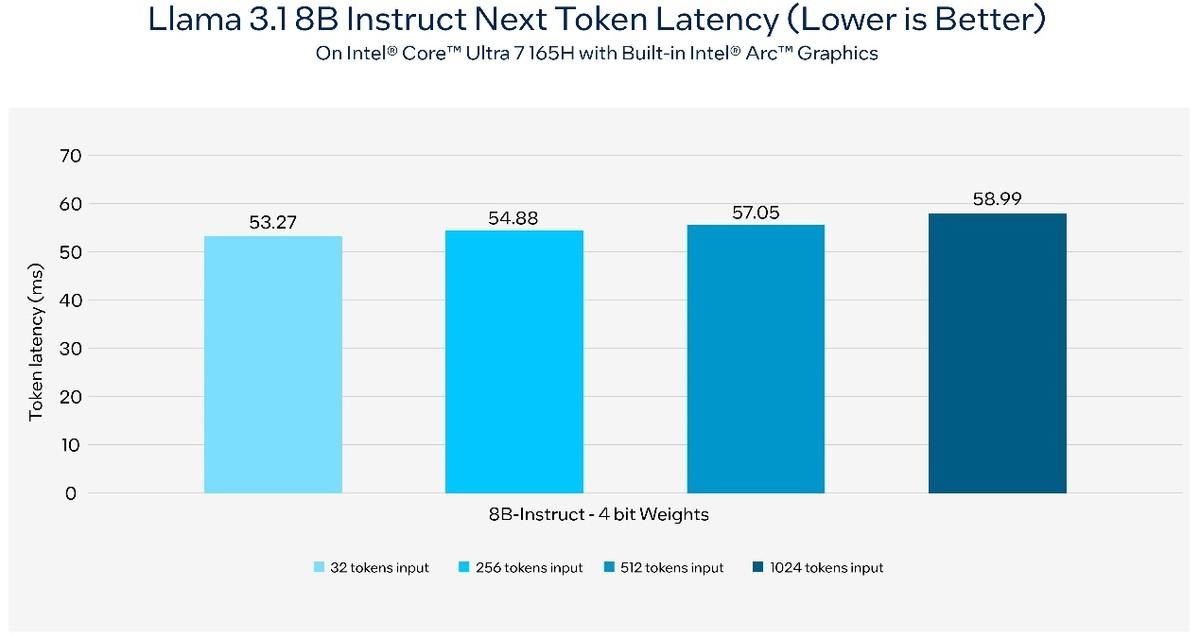
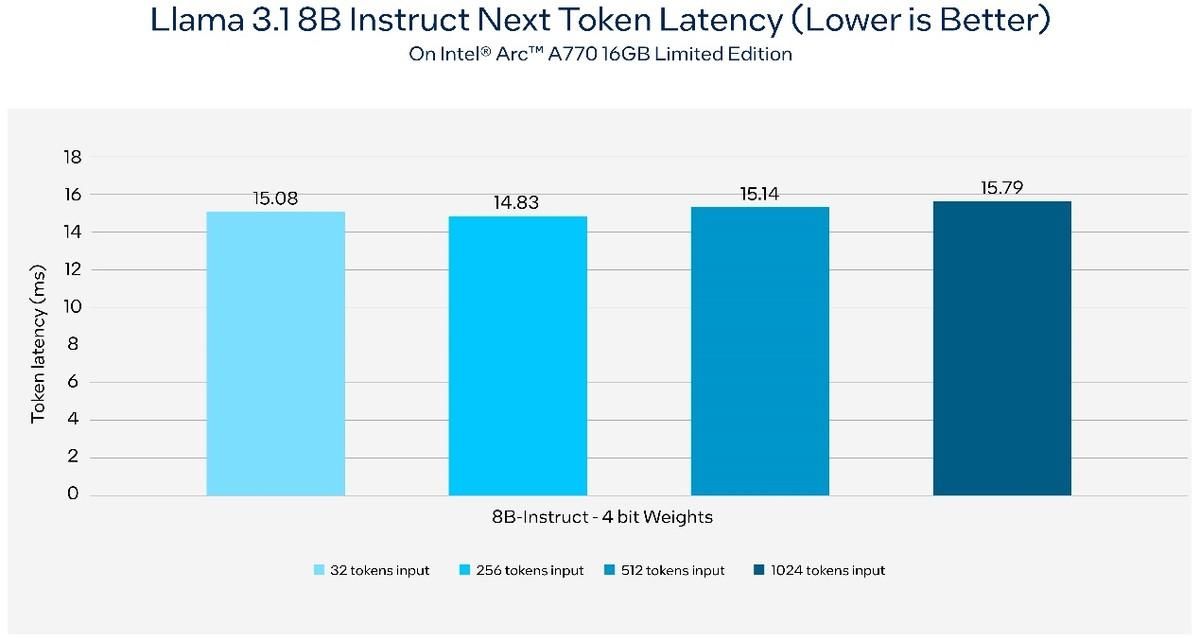
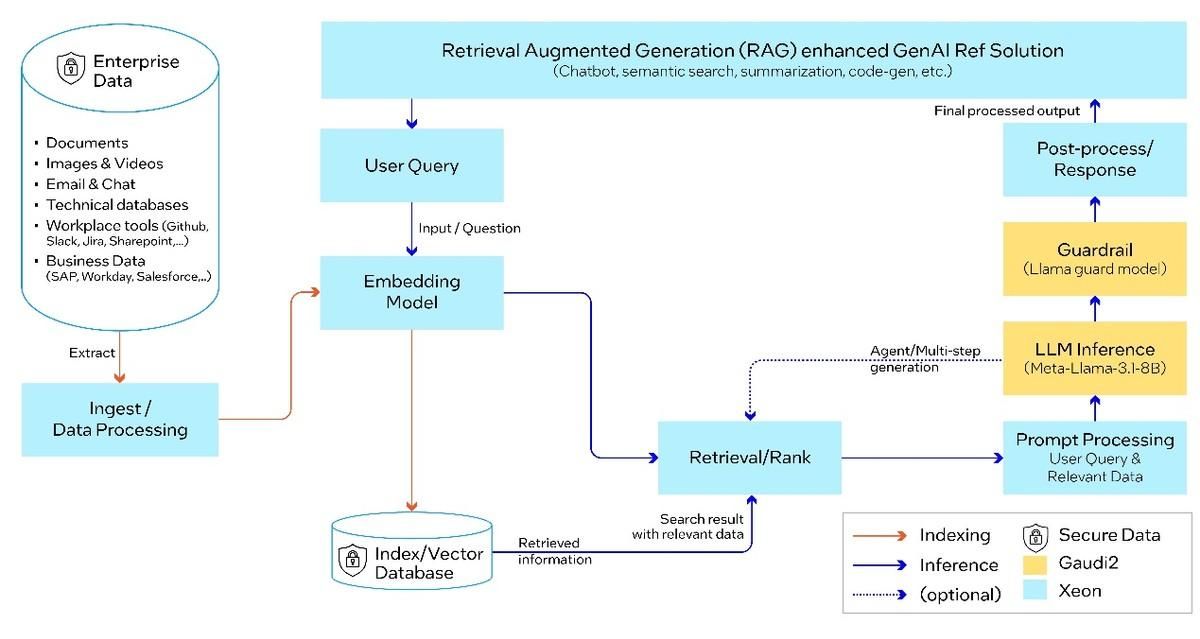
终结闭源霸权 Meta Llama 3.1横空出世!Intel第一时间适配并加速
65
0
相关文章
近七日浏览最多
最新文章
标签云
intel
酷睿
xbox
gtx
显卡
快科技
高通
苹果
咸鱼翻身
英特尔酷睿
英特尔
处理器
cpu
gpu
bios
联想
ddr5
内存
moto
骁龙
ultra
英伟达
芯片
h6
哈弗
小红书
腾讯
锐龙
华硕
ibm
硬盘
固态硬盘
npu
付建
上交
离职
律师
非指定赠与
nvidia
geforce
黄仁勋
微星
amd
比尔
服务器
平均售价
雷军
中国
大模型
上下文
新闻学
deepseek
首席执行官
xt
rx
讯景
跑车
系列芯片
radeon
nsa
grok
埃隆_马斯克
华为
周鸿祎
文章
郁风
胡锡进
英伟达芯片
非公版
微软
知名企业
索泰
主板
新加坡
垄断
烟草
互联网
谷歌
立案
pc
印尼
显存
美光
rtx
pdf
ows
华为mate
游戏
matebook
ces
摩尔
张建中
神话
寒武纪
张旭光
人工智能
特朗普
霍华德
系列显卡
核弹ai芯片
美国
liming
直播
训练成本
钛媒体
a100
大语言模型
美ai公司
英伟达h100
字节跳动
blackwell
亚马逊
反垄断
越南总理
股票
埃利奥特
史蒂文斯
时代周报
应收账款
太阳能电池
郑州
富士康
rain
机器人
jonathan
初创公司
john
归母净利润
研报
第一财经