


友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
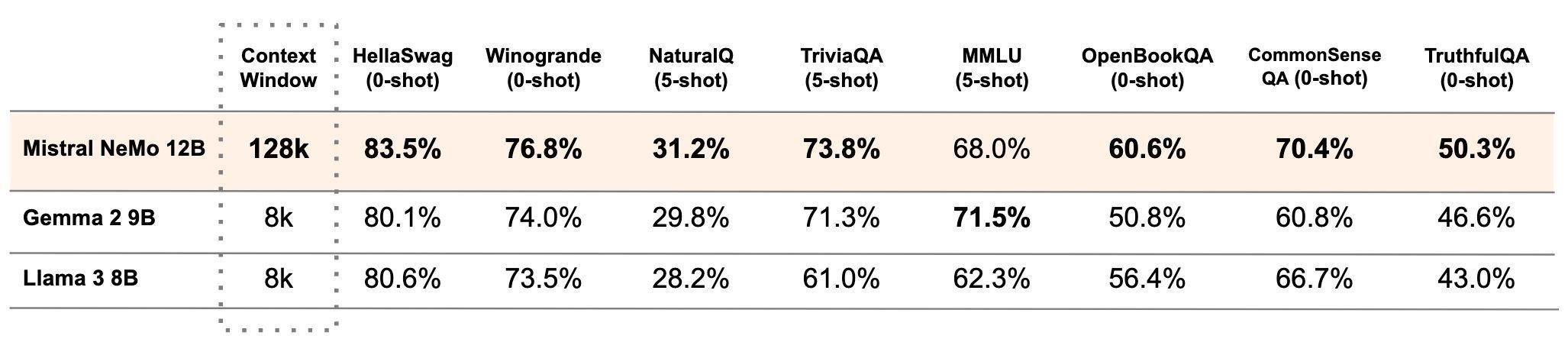
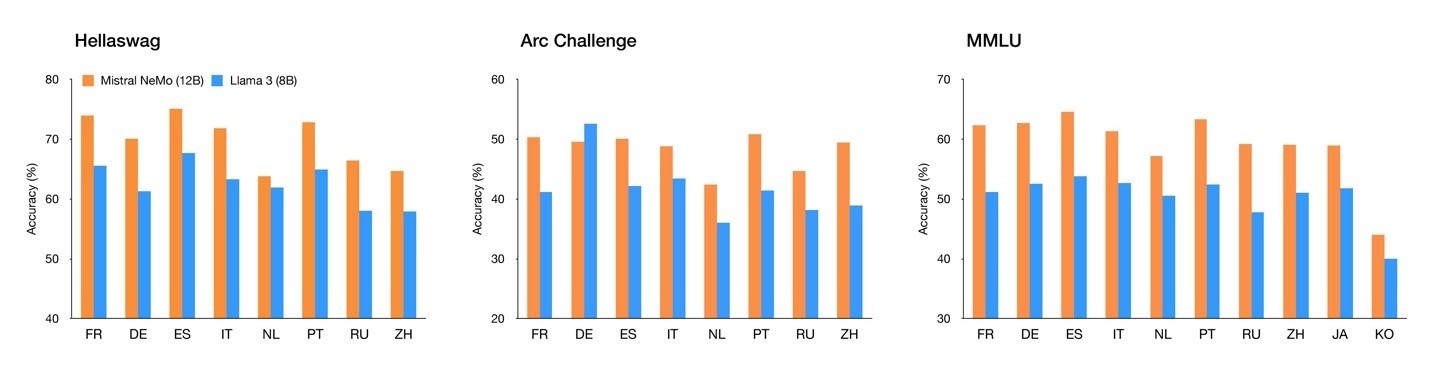
英伟达联合发布 Mistral-NeMo AI 模型:120 亿参数
19
0
相关文章
近七日浏览最多
标签云
中国移动
人工智能
通信
通信技术
ai
谷歌
李世石
阿尔法狗
哈萨比斯
诺贝尔奖
alphago
科学
教授
诺贝尔物理学奖
华为
项立刚
孙凝晖
中科院
任正非
天眼查
科大讯飞
南京
联合国
中兴通讯
中国联通
中国电信
nlp
操作系统
股票
科技
万军伟
上交所
英伟达
ipad
乔布斯
苹果
网络安全
上海
app
初创公司
微软
美股
戴尔
芯片
愿景基金
孙正义
股价
软银
arm
联想
inc
山东省
济南
金融服务
金融科技
新加坡
减持
价值投资
北京商报
北京
人工智能技术
mate
花旗
e30
大数据
健身房
云计算
物联网
a股
三星
大陆
台积电
中芯国际
芯片代工
芯片制造商
台湾积体电路制造
收盘
纳斯达克
道指
高通
骁龙
黄仁勋
国产手机
华为手机
3nm芯片
英特尔
amd
芯片供应
亚马逊
美国
cpu
路透社
三星电子
埃利奥特
gpu
史蒂文斯
netflix
保罗
国会
巴菲特
希金斯
国会山
投资收益
美元指数
中概股
美联储
机器人
美光
sk
郑州
富士康
美债收益率
comex
小鹏汽车
道琼斯工业平均指数
马斯克
日元
百胜中国
优步
新东方
股票回购
标普
期货
美国商务部
sk海力士
冲高回落
lucid
美国经济
张弛