“AI大模型即将遇到数据荒”这件事,从2023年开始就成为了AI开发者对未来最大的担忧,甚至有研究团队已经给出了高质量语料数据将会在2026年耗尽的预测。由此也使得手握大量数据的互联网内容平台、新闻机构、出版商突然发现,在AI时代“卖铲子”这活不仅英伟达能干,自己好像也能做。

而AI厂商则很快发现,自己头上的大山除了英伟达,还要多出个数据供应商。尽管谷歌、OpenAI等实力雄厚的大厂可以选择“银弹攻势”,一边找英伟达买算力卡,一边与Reddit等网络社区及新闻媒体达成合作,但资金丰沛的大厂毕竟是少数,绝大多数初创企业、哪怕是AI独角兽都缺钱。
AI大模型需要持续投喂数据来进行迭代,可AI厂商缺钱又已经是普遍现象,如此一来就有厂商选择了用技术手段来“强取”数据。日前有消息显示,AI独角兽Anthropic无视知名维修网站iFixit的条款,使用爬虫ClaudeBot在24小时内疯狂访问近百万次。
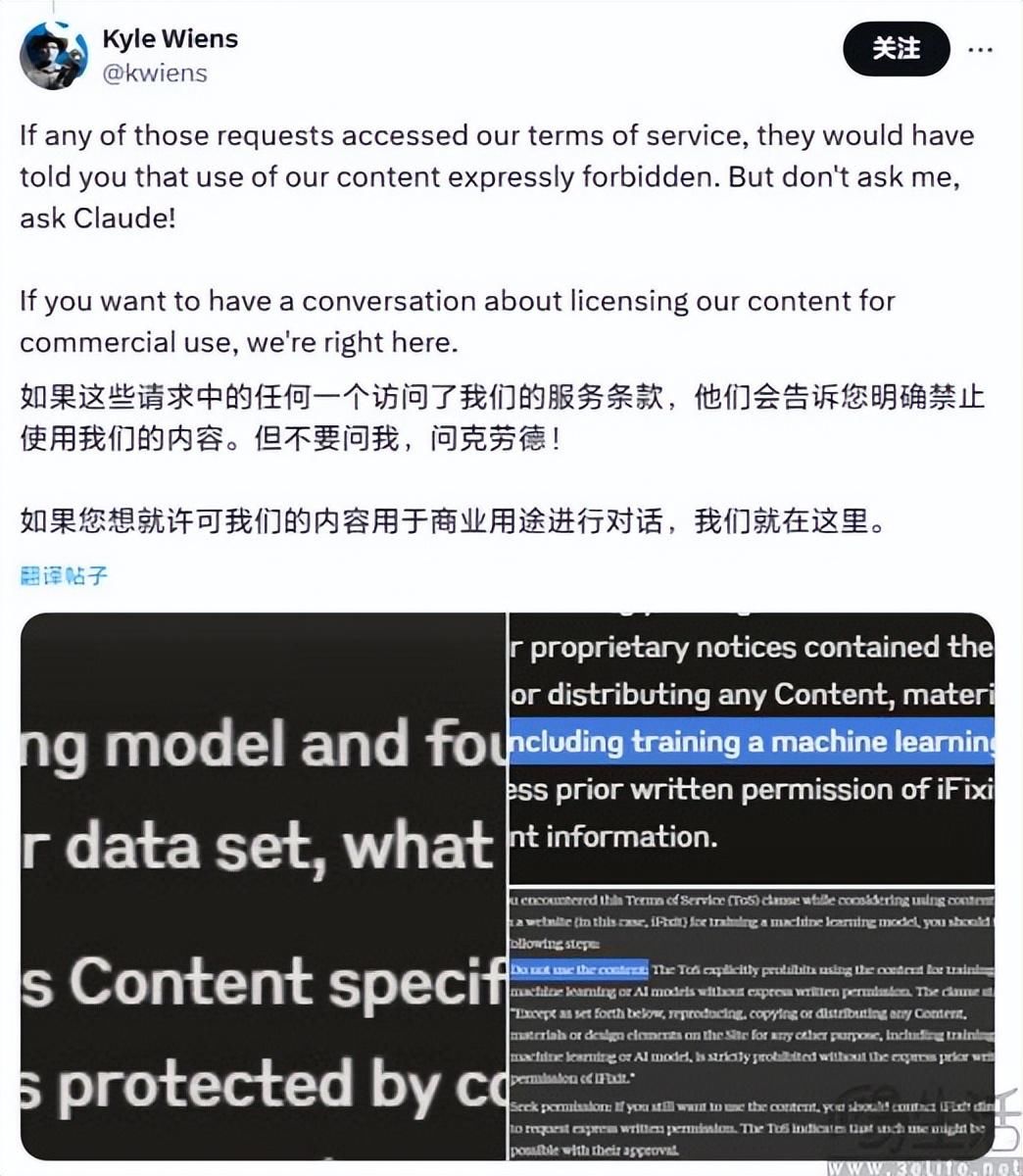
以至于iFixit CEO Kyle Wiens直接在社交平台向Anthropic隔空喊话,“你真的有必要在24小时内访问我们的服务器100万次吗?你不仅在不付费的情况下获取我们的内容,还占用了我们的devops资源,一点都不酷!”此外Kyle Wiens还进一步表示,“如果你想要跟我们谈谈内容许可和商业用途的话,我们就在这呢。”

作为全球知名的消费电子产品维修网站,iFixit的市场竞争力就来源于网站上提供的几乎任何类型、任何型号电子设备对应的免费维修手册、解决方案,以及iFixit用户社区。这些电子产品的维修知识无疑就是iFixit的立身之本,因此iFixit方面也在其robots.txt文件中添加了一行特定于Anthropic爬虫的禁用指令。
随后Anthropic方面回应称,他们尊重robots.txt协议,并在iFixit实施禁令后遵守了相关规则。其实不仅仅是iFixit,全球规模最大的外包服务撮合平台Freelancer同样也是Anthropic的受害者,该公司CEO Matt Barrie也表示,ClaudeBot是最激进的爬虫,Freelancer在四小时内收到了来自Anthropic爬虫的350万次访问,远超其他AI爬虫的访问量。
对于iFixit、Freelancer这种专注于细分赛道的“隐形冠军”,24小时内数百万次访问请求已经算得上是一次小规模的分布式拒绝服务攻击(DDoS)了。对此,Anthropic方面表示正在调查此事件,以确保其爬虫活动对同一域名的访问频率最小化,从而减少干扰。
那么问题就来了,Anthropic其实不缺钱,毕竟作为OpenAI的第一劲敌,仅亚马逊一家就对其投资了40亿美元。Anthropic方面甚至在本月初联合风险投资公司Menlo Ventures共同推出了一只1亿美元的基金Anthology Fund,为早期的AI初创公司提供支持。
没错,身为AI独角兽的Anthropic已然开始“提携后辈”,玩起了大公司标配的战略投资。对此,似乎就只能用Anthropic的经营策略是“该省省,该花花”,能不花的钱就一定不花来解释了。

正因如此,Anthropic的做法才让iFixit、Freelancer的CEO“破防”。作为一家在业界颇有声望的AI独角兽,Anthropic的做法毫无疑问是开了个坏头。要知道反爬虫策略本身是不可能完全杜绝爬虫的,因为信息只要对外提供,就必然有被抓取的可能。在这一基础上的robots.txt,其实就是一个针对网络爬虫的君子协议,也正是谷歌、雅虎等大厂的带头遵守,才有了过去二十年间互联网世界的秩序。
现在明明Anthropic是有向内容平台购买数据的预算,却偏偏选择用技术手段来“零元购”,岂不是就意味着其他囊中羞涩的AI初创企业也会有样学样。可偏偏当下是AI创业的热潮,做AI的厂商不知凡几,如果大家都效仿Anthropic这一玩法,高频次、大流量的访问必然会让网站“压力山大”,已经与DDoS网络攻击行为无异了。
面对DDoS这种目前最简单、也是最粗暴的网络安全破坏活动,几乎只有两个有效途径可以解决,即用更大的带宽资源来容纳超预期的网络请求,或是使用流量清洗来过滤掉无用流量。很遗憾的是,这两种策略都不便宜,中小网站通常是买不起的。
AI厂商对于数据的需求永无止境,可偏偏不愿意付钱,而一般的网站有数据、却缺乏保护这一资产的手段。如果这次Anthropic仅仅是“有则改之”,连一个道歉都没有的话,后续内容平台卖数据的生意恐怕就要难做了,互联网世界可能会开始进入周礼崩溃后的春秋战国时代。
在AI厂商的爬虫高频次访问下,中小网站别说卖数据,可能就连正常的运营都会受到影响。如果想要让自己的网站免受爬虫打扰,“自污”策略或许很快就会普及。而所谓“自污”其实很简单,毕竟AI厂商的爬虫希望获得数据来训练AI,可假如数据本身不可用呢?

关心AI大模型的朋友对于“AI投毒”这个词想必不会陌生。就在不久前,《Nature》封面刊登了来自牛津大学、剑桥大学等机构的研究论文,内容就是AI训练AI会出现不可逆转的缺陷,进而使得模型性能下降。这篇文章尽管在业界充满了争议,但其中给AI投喂低质量数据会导致模型劣化却收到了共鸣。
如今,数据投毒攻击(Data Poisoning Attack)已经是一个AI研究领域不可回避的问题,只需要训练集有不到1%的数据被污染,大模型输出内容的准确率就会大幅下降。用谎言去验证谎言得到的一定是谎言,如果数据集中的参数本身就有问题,得到的回答自然就是错漏百出。

想要得到高质量数据需要凝聚人类的智慧,但想要毁灭它可就简单多了。如果AI厂商不保持克制,一旦内容平台的运营者达成共识,用污染自家数据的方式来解决这个问题,遭遇数据荒的时间恐怕就会近在眼前。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com