C114讯 5月24日消息(张晓宝)5月23日,由CIOE中国光博会与C114通信网联合举办的2024中国高质量发展论坛第四场——“AI时代:数据中心光互联技术新趋势”研讨会成功举行,京东光互联架构师陈琤在会上分享了关于《高性能计算网络中的光互连》的主题发言。

京东在高性能计算网络领域起步较早,持续在多个代际的智算拓扑上做了大量的投入,应用场景涉及到了推荐算法、智能客服,AI售卖租赁、数字人直播等等。
智算网络拓扑一般分为两类独立的网络,其一是接入/存储网络,主要实现CPU之间的互联;其二是计算网络,主要进行GPU节点数据的并行协同。
整体来看,智算网络对于光互连的要求主要集中于三方面,即大带宽、低成本和低延时。
光模块与大带宽的关系
数据链路带宽方面,首先要实现的是GPU与GPU之间并行多路的通信,需要注意数据传输过程中链路带宽的情况,在计算节点内部互联中一般可采用C2C Full mesh的方式,连接速率可达数百GB/s。
如要实现不同GPU出口的通信,则要通过PCle与网卡连接,在进行串并转化后进而通过光模块、计算网络实现跨端口连接。因此,当前许多厂家均在提倡光学输入/输出(OIO)的形式,以突破高速互联的瓶颈,这也是当下的一个发展方向。
在网络设备/光模块带宽演进方面,当前智算网络主要部署的是50G Serdes的交换机和光模块,光模块类型选择则以200G/400G等为主。当单节点容量达到51.2T时,根据对网络可拓展性的要求会去选择不同的拓扑类型,北美的一些厂家会选择64x800G OSFP,国内厂家则采用128x400G QSFP 112的封装,但二者产业链是通用的。
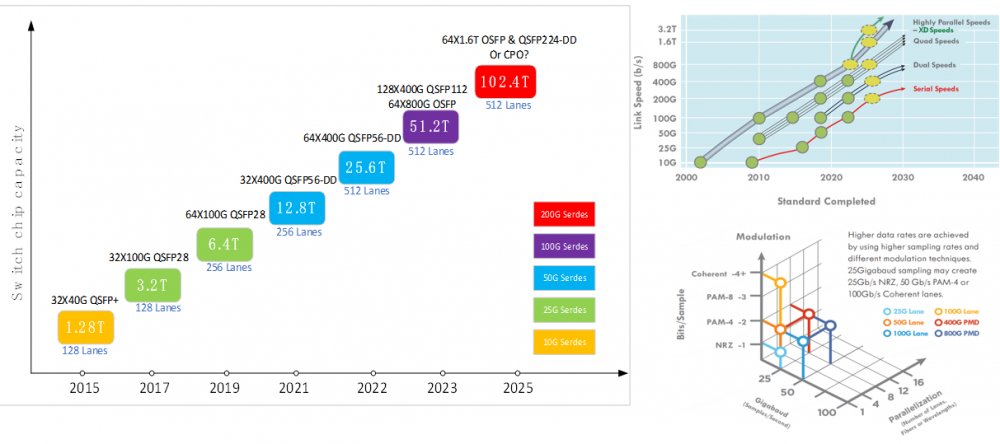
若未来单芯片交换容量达到102.4T,可插拔光模块依然可以支持高密度大容量的光互连应用,可以选择64x1.6T OSFP和QSFP224-DD。。CPO也是热门的解决方案之一,它要继续解决可靠性的问题,还要解决建设部署中的可维护性问题。
如何降低光互连成本?
在降低光互连低成本问题中,硅基光子技术是潜在的降成本方案之一。硅光并非是全新的技术,但就数据中心应用而言是比较新的产品,当前112G per lane模块的供应链上游集中于少量光器件厂家,因此硅光光模块可以据此介入,以打破供应紧张问题。
特别硅光模块是可以覆盖解决2km以内的所有数据中心应用场景需要的,因此京东也在进行相应的认证等工作,相信不久的将来也能真正的部署到当下网络中。
线性直驱光模块LPO/LRO当前也是比较热门的应用方向,在112G per lane时代,借助于ASIC驱动能力足够强的特性,可以将光模块作减法,即去掉DSP或CDR的部分,进而可降低光模块的复杂程度,以达到降低成本的目的。
但其也面临了一些挑战,如兼容性与互联互通的问题,要考虑ASIC芯片对其的支持情况、不同厂家间互联情况、新旧模块互联互通的情况等等问题。
还有演化可持续性的问题也要考虑进来,如112G已可支持LPO,但如发展至224G等,就要考量LPO是否支持的可行性了。
智算网络低延时问题
在低延时方面,如要实现整体协同的运算保障,不同的计算节点间的GPU延时问题势必会大大降低运行效率,那么哪些因素通常会导致延时呢?
首先是基于协议,GPU的网络最初基于InfiniBand(IB)的协议形式较多,在数据传输中可绕过CPU的参与,实现了不同计算节点间GPU缓存之间的数据通信,大大减少了基于协议的通信延时。
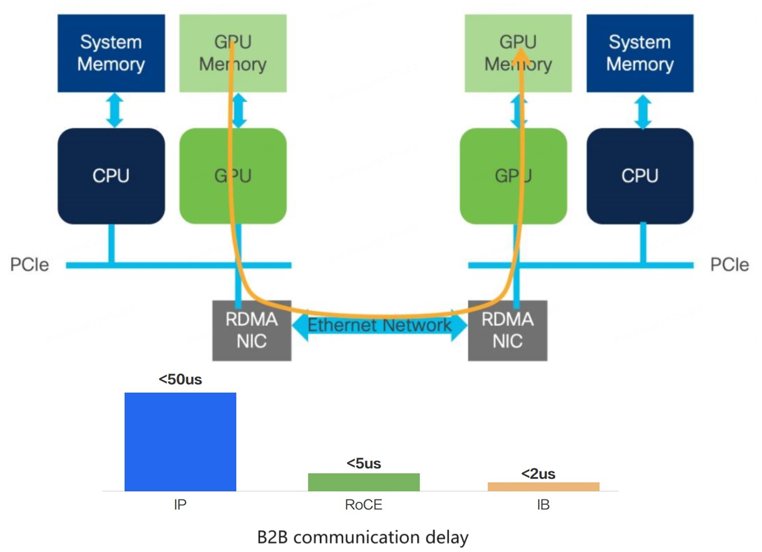
基于传统以太的协议,则要CPU介入到通信整个过程,因此其延时会比较长。
在智算网络中用到的是一个较为折中的方案,即RDMA方案,可借用以太协议的封装将RDMA的内核封装进去,进而实现共用以太网的设施以实现降低延时。
其次则是链路延时,因为GPU与GPU之间的通信要经过leaf-spine架构,并要进行光信号转换,实现数据互联,其过程中各环节也必然产生各种不同的延时。
如在决策类模型的时延中,可优化项为光模块中的信号恢复单元导致的延时。而在生成式模型的延时中,主要是数据传输时间导致的延时为主,而物理链路导致的延时实际占比极小。因此,这时候系统延时会对带宽利用率更为敏感,要根据模型不同去优化延时的不同方向。
最后陈琤总结到,相较于传统数通网络,智算网络带宽的增长也会更迅速,低成本互联有赖于新技术的支撑,如硅光、LPO/LRO等。另外,不同的模型对延时的要求是不一样的,要优化的方向会有所区别。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com