友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
联想CTO芮勇:左手是大模型,右手是智能体
44
0
相关文章
近七日浏览最多
最新文章
4月18日,第十届联想创新科技大会Tech World在上海举行。联想集团高级副总裁、首席技术官芮勇博士表示,不能再单纯地用大数据+大算力+大网络来堆砌大模型,而是要超越大模型,探索更接近人类的思维和行为方式。

2022年11月底,ChatGPT横空出世,掀起了大模型的热潮。从百亿参数,到千亿参数,再到万亿参数,大模型能力越来越强大;从语言模型,到视频模型,再到最近的音乐模型,大模型的表现越来越出色;AI历史上,无论是统治语音识别30年的隐马尔可夫模型,还是称霸整个90年代的支持向量机,从来没有任何一个技术,能够像今天的大模型这样强大。大模型是AI历史上的重要里程碑,它开启了人工智能发展的新纪元。芮勇博士称,但是它的理解和规划能力还很有不少局限性,这些局限性需要解决。
今天的大模型没有真正地理解语言和理解世界,也没有推理和规划能力。它只是根据高维语义空间的联合概率分布,来连接它之前见过的海量信息片段。
大模型一方面能力很强,另一方面有局限性。所以要'扬长补短',扬长:我们要持续发扬并增强大模型的强大能力。长短:我们要打造基于大模型的智能体技术,真正解决应用场景的问题。联想的理念是,左手是大模型,右手是智能体,两手都要抓,两手都要硬。
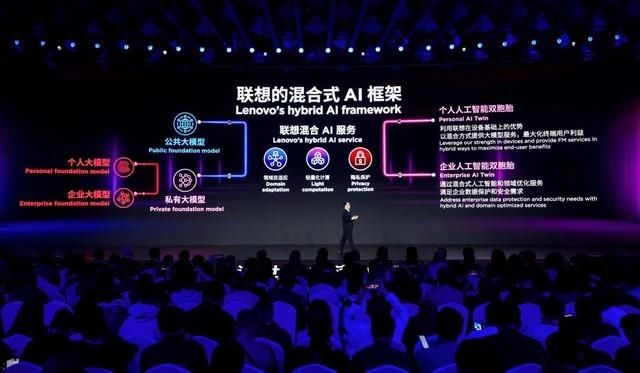
联想倡导混合人工智能框架,是公有大模型和私有大模型的混合。从技术角度看,还有几个重要维度的混合。
首先,小模型不会消失。今后一定是基于大模型和小模型混合的“意图理解”技术。大家知道信息论里面的熵entropy是度量信息量的。越有序,熵越小,越无序,熵越大。联想使用交叉熵crossentropy 损失最小化原则,将意图理解任务最优地分配给大模型和小模型,从而兼顾精准度和复杂性。
第二,基于CPU、GPU、NPU混合调度的“异构计算”技术。今天,在大模型的训练和推理过程中,瓶颈往往不在于芯片算力,而在于数据传输。这个方程式是说,我们来同时优化计算负载和数据传输,使总体执行时间最短。
第三,基于模型微调(SFT)与检索增强(RAG)混合的“智能问答”技术。相信很多人都听过RAG和模型微调。这两种技术哪个更好呢?其实,这两种技术各有长短。
第四,基于硬件加密与全栈可信架构的混合“隐私安全”技术。光用硬件是不够的,光用软件也是不够的。我们知道,在前量子时代,我们是通过把一个非常大的整数进行质数分解进行加密。但是在后量子时代,这就不够了。这个方程式通俗地讲,就是通过在一个高维实数空间里进行因式分解来进行加密。
可以看到,这里讲到的4种混合式技术,需要端边云的协同,需要软件硬件的协同,需要传输与计算的协同。联想的新IT架构“端边云网智”为混合式技术的实现提供了强大支持。
(8664661)
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com