2024年是不是AI大模型创业公司的寒冬?这是知乎“科技创业者的2024”圆桌讨论中一个非常热门的话题。但从现在来看,这个问题的答案似乎已经呼之欲出了,今年对于AI赛道的创业者来说极有可能就是冰冷彻骨的一年。如果说大名鼎鼎AI绘画工具Stable Diffusion背后的Stability AI寻求出售还是特例,但如今已有越来越多的消息显示,许多叫得上号的AI初创企业同样也在寻找买家。

日前根据海外媒体的报道显示,由前OpenAI工程副总裁David Luan与两位谷歌Transformer架构提出者Ashish Vaswani、Niki Parmar联手创立AI初创公司Adept,也再考虑出售。而另外一家由前谷歌、Meta研究人员创立的初创公司Reka AI,同样准备以10亿美元的价格“卖身”数据公司Snowflake。
Stability AI走向穷途末路,似乎与该公司创始人Emad Mostaque持续不断地“作死”密切相关,并非其本身的技术落后于时代。要知道,即使是陆续失去了核心开发团队、创始人,整个公司陷入群龙无首的状态,该公司也在近期推出了AI音频模型Stable Audio Open以及Stable Artisan Discord机器人服务。
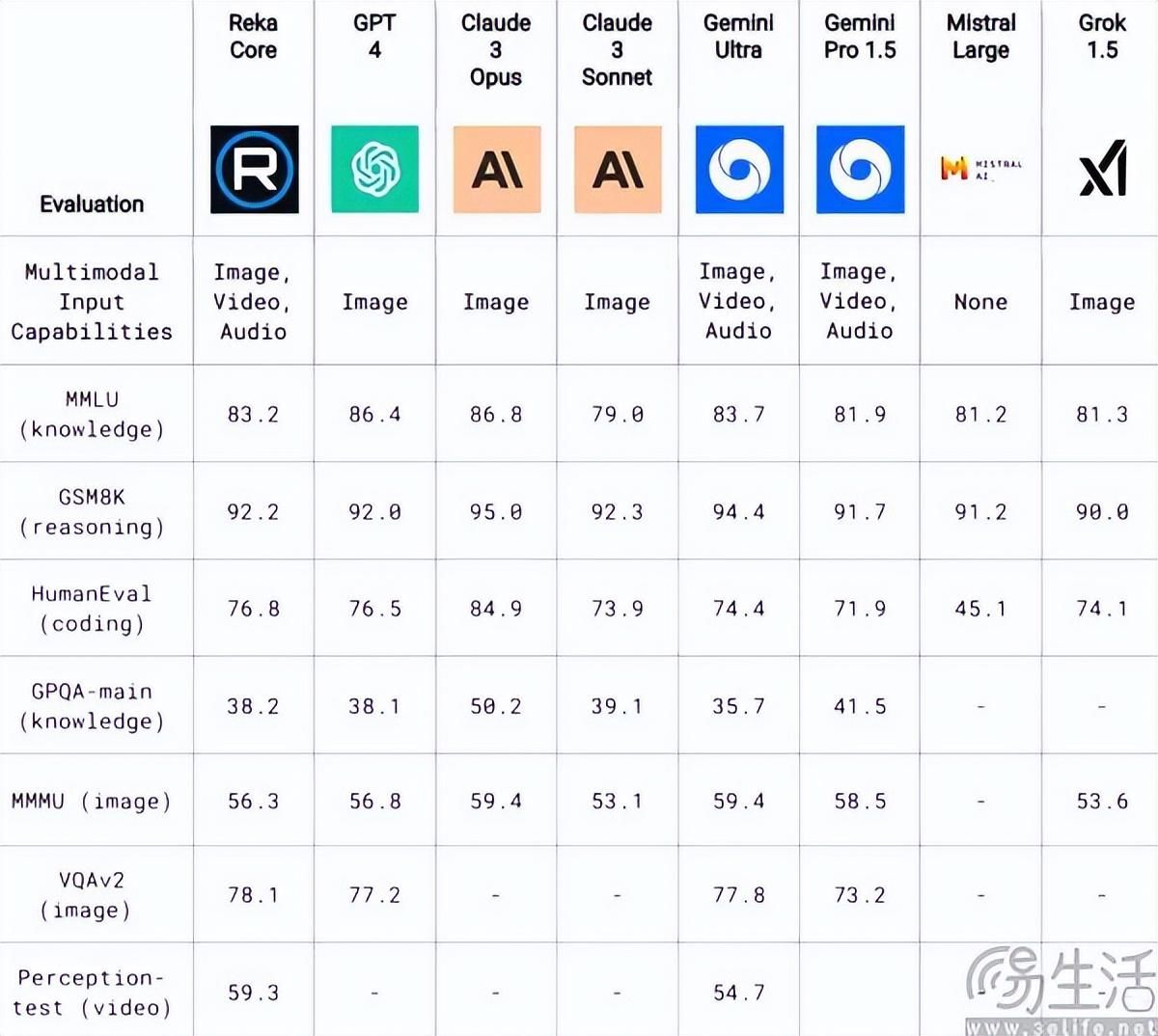
如果说Stability AI的困境是非典型的,那么Adept和Reka AI则是AI初创企业在2024年遭遇倾覆之危的典型。以Adept为例,一年前这家公司还是风光无限的AI独角兽,成立仅一年就获得了3.5亿美元融资、估值一举突破10亿美元,也得到了微软、英伟达等一众巨头的青睐。其主要是开发AI Agent(AI智能体),第一个产品就是ACT-1大模型,特点是能基于用户的指令、分步骤给出反馈,并且后续发布的多模态模型Fuyu-Heavy,也做到了如同ChatGPT一般对于文本和图像的高效理解。
其实Reka AI的情况也差不多,该公司同样有能理解文本、图像、短视频、音频片段多模态的AI助手Yasa-1,以及号称能力媲美GPT-4和Gemini Ultra的Reka Core大模型。然而遗憾的是,这些有技术的AI初创企业最终却走向了寻求出售。
那么问题出在哪里呢?其实就像我们三易生活早前曾在相关内容中提及的那样,这一轮围绕AI大模型的浪潮,本质上其实是巨头的游戏,毕竟大模型乃至Agent都太费钱。
众所周知,训练一个AI大模型需要大量的计算资源,其中以英伟达的H100为参考,在2023年上市时,每张H100的价格就在2.5万-3万美元之间。当然,训练大模型显然不可能只用1张计算卡,以至于高通、英特尔、谷歌要组成AI联盟来对抗英伟达。空有算力也不行,没有语料来作为“燃料”,大模型的智能就是无根浮萍,所以采购数据以实现打模型的持续迭代也是需要一笔巨资。
除此之外,训练大模型需要的水和电也是天文数字,AI大模型更是不折不扣的“电老虎”。根据国际能源署在2023年的测算,训练大模型的数据中心变得越来越耗电,其用电量占全球电力消耗的1.5%至2%,大致相当于整个英国的用电量,预计到2030年这一比例将上升至4%。此外,OpenAI训练GPT-3的耗电为1.287吉瓦时,大约相当于120个美国家庭1年的用电量。但这还仅仅至是训练AI大模型的前期电力消耗,仅占其实际使用时所消耗电力的40%。
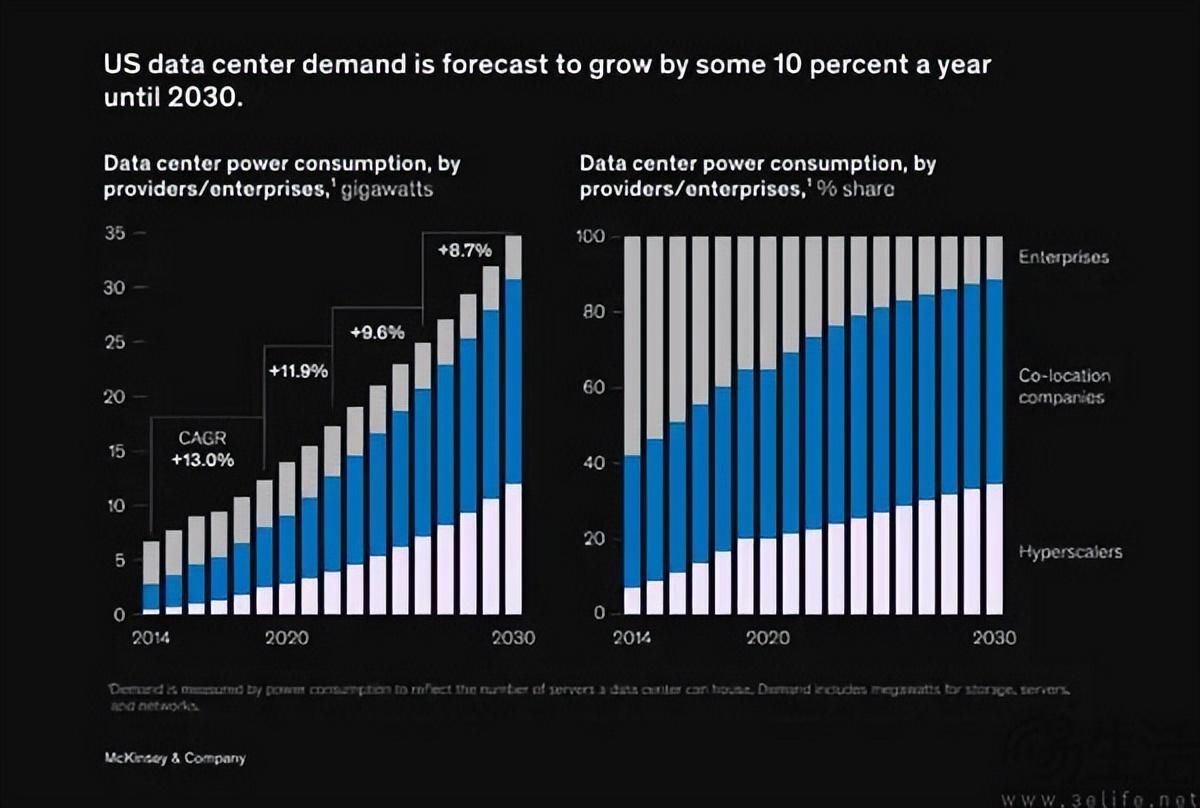
用更多的电力驱动更多的GPU进行训练,还需要大量地消耗水资源来冷却芯片,为了让数据中心稳定运行,自然就需要使用大量的水来进行散热。根据谷歌在ESG报告里透露的数据,在2023年有52亿加仑的水用于其数据中心,比2021年增加了20%。为什么进入2024年后,更简单、更专业的小尺寸模型突然开始吃香,节能其实才是微软、谷歌等巨头青睐它的原因。
当然,在科技圈里新概念需要“烧钱”其实是正常现象,投资机构对此也心知肚明。实际上,2024年并不是投资机构不给AI赛道投钱了,而是初创企业想要继续拿到大额融资变得愈发困难。因为巨头们也开始发力,直接导致初创企业的生存空间被挤压。AI初创企业拿到投资的机会是在2023年,这一年ChatGPT才刚刚重燃外界对于AI的热情,此时“大公司病”也阻扰了这些巨头快速拿出相关产品。

Reka AI、Adept、Stability AI此前获得的大笔融资都发生在2023年上半年,其实就是最好的证明,到了2023年秋季,拥有技术、数据、算法,以及资金优势的巨头正式加入这场盛宴,也使得AI初创企业的竞争压力呈指数级提升。与此同时,AI大模型领域的技术进步开始放缓,相比于去年同一时期,大模型的性能迭代遇到瓶颈目前几乎成为了全行业面对的共同难题。
纵观Reka AI、Adept这类遇到问题的初创企业,他们都有一个共同的特点,那就是做着与巨头差不多的工作。在大家的技术水平没有本质差异的情况下,巨头却有应用场景、能直面用户,初创企业则缺乏这种能力,因此也导致后者自然会泥足深陷。但月之暗面就是一个正面的典型,虽然他们的Kimi大模型未见得就比百度的文心一言强,但却别出心裁地提掀起了长文本之战。

此前在3月18日,Kimi方面将大模型上下文输入限制突破至200万汉字,这一突破性的进展直接让Kimi实现了破圈。自此,长文本就成为了月之暗面的招牌,也引来阿里、腾讯的大手笔投资。且不提未AI产品尚未找到合适的商业化模型,这种巨头都没有做到的事情如果能实现差异化竞争,即使在投资热情减退的2024年,AI初创企业也并非完全没有机会。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com