



友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
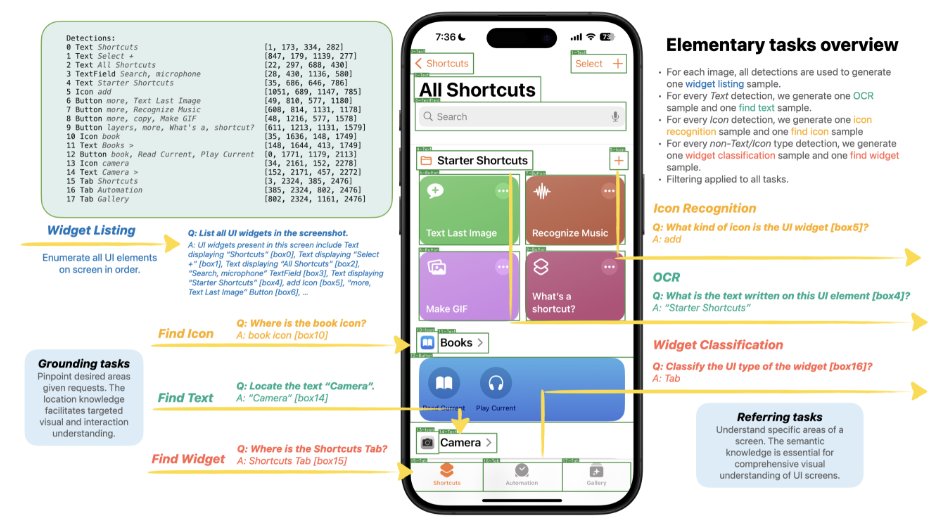
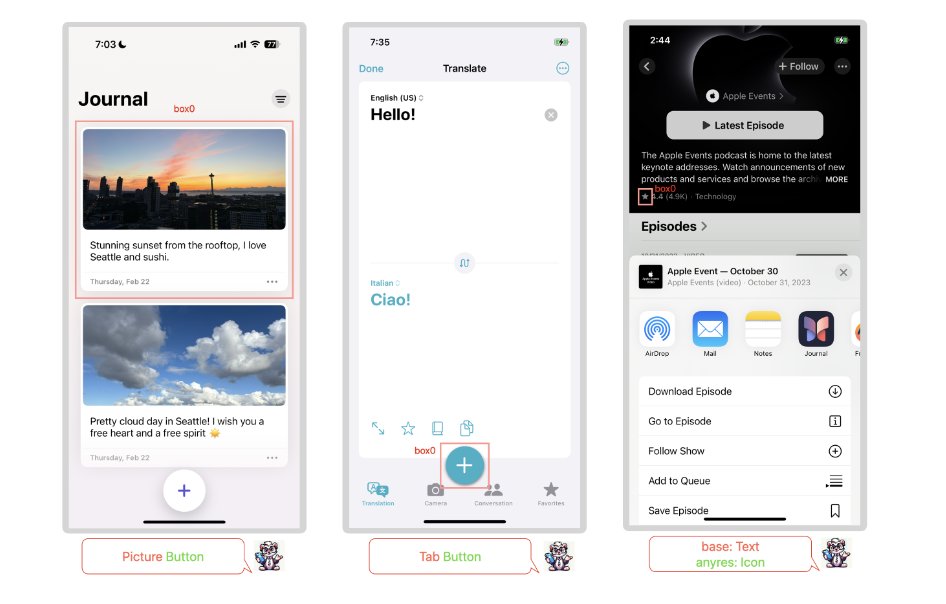
苹果介绍 Ferret-UI 多模态大语言模型:更充分理解手机屏幕内容
20
0
相关文章
近七日浏览最多
最新文章
标签云
三星
ui
android
智能手机
ultra
手机充电
动力电池
自动泊车
魔兽世界
安卓
oppo
液晶仪表
无线充电
高德地图
吉利
flyme
领克
名爵
跑车
上汽名爵
弯道超车
app
nfc
carplay
苹果
保时捷
鸿蒙
谷歌
pi
驾驶模式
新能源车
途观l
液晶仪表盘
折叠屏
apple
siri
ios
聊天记录
写真
github
互联网时代
36氪
二选一
雷军
原型车
量产车
小米手机
市场份额
TimCook
人物访谈
库克
天猫
京东
优惠券
官方渠道
iphone
三折叠屏手机
国行
港版
手机
wifi
相机按键
欧盟用户
换屏
泡沫
曲面屏
倒贴
国产手机
华为手机
罗玉凤
预售
max
摄像头
沙漠金色
相机
客服
苹果手机
安卓手机
微信
腾讯
开发者测试版
iphone手机
货车
红星
礼泉县
果汁厂
市监局
河南
印度
鸿海集团
富士康董事长
鸿海科技集团
税收
苹果税
互联网
垄断
企业
欧盟
面试
富士康
刘扬伟
造车
河南省
新iphone
新款iphone
cpu
高通
骁龙
arm
期货
红枣
仓位管理
股价
俞敏洪
便秘
减肥
海带
放射性物质
美国运通
股票
伯克希尔
减持
巴菲特
可口可乐
mac
英伟达
郑州
gpu
redmi
lcd
4g
国产品牌
ipad
人工智能
乔布斯
科技
苹果公司
中国大学
冲高回落